WebScraper manual
What follows is a full run-down of WebScraper's controls and features. A quick-start guide is here and the product home page and download are here.
- Scan tab
- Scanning a list of urls
- Authentication
- Output file format tab
- Output filter tab
- Output file columns tab
- Results tab
- Post-process output file
- Class helper
- Regex helper
Scan tab
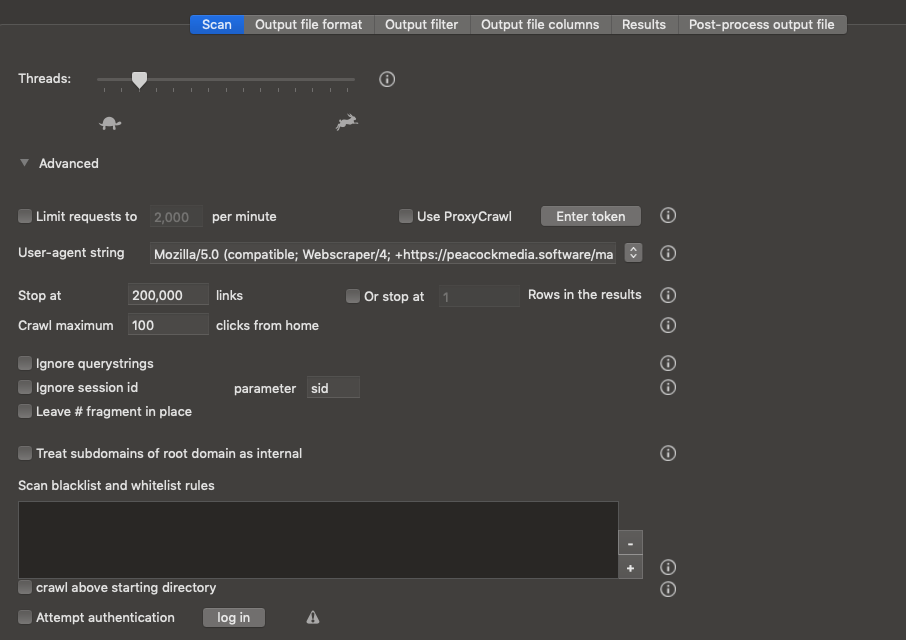
These settings control the actual scan or crawl. If you want to scan an entire site (ie every page within the same domain) then you may be able to ignore this tab. There may be settings that you need to tweak in order to scan your site properly, or you may want to use the black / whitelisting to limit the scan to a particular section of the site.
Note that the engine has a 'down but not up' rule. ie if you start within a 'directory' such as peacockmedia.software/mac/webscraper then the scan will automatically only include pages within /webscraper.
Threads / Limit requests / Use ProxyCrawl: Use these settings to 'throttle' or rate limit your crawl.
Threads controls how many simultaneous requests can be open. The default is 12 which will cause the scan to run pretty quickly if the server can cope. The maximum is 50 but in practice this control makes little difference past a certain point. Some servers may stop responding after a while if the rate is too high. Moving this slider to the far left will limit the scan to a single thread, ie each response is received and processed before the next is sent.
This is a crude control over the rate. It may be much better to use rate limiting (read on....)
Limit Requests to X per minute: The engine will be smarter if you use this control. It'll still use a small number of threads but will introduce calculated delays so that the overall number of requests doesn't exceed the number you set per minute.
Use ProxyCrawl: It's not unusual for a website to respond to the same IP address a limited number of times (and it may use other factors besides IP address to identify a requester). In these cases it's necessary to use a service to distribute your requests via many proxy servers. If you want to use ProxyCrawl you can enter your token here.
Stop at / Crawl maximum links from home allows you to limit crawl by the number of links traversed, the number of levels (depth) or by the number of results in the output table.
Ignore querystrings / Ignore session id may be necessary in cases where spurious information in querystrings or specifically a session id are causing the scan to run on much longer than it should, or for ever.
Treat subdomains of root domain as internal allows you to decide whether to include subdomains, eg blog.peacockmedia.software in your scan
Blacklist and whitelist rules allow you to set up rules to control the scope of the scan. You can set up a rule so that the scan will ignore links matching a certain string, or 'only follow' links matching a certain string. (There's no need to set up a rule if you want to limit your scan to a certain directory - see the note at the top about the 'down but not up' rule). The strings you enter are a 'partial match'. Not regex, although you can use certain characters such as * to mean 'any number of any character' and $ to mean 'at the end'.
Note that these rules control the scope of the scan. You can filter separately the pages that you want to extract information from. (see Output filter)
Render page (run javascript) Don't use this option unless you know that you need it. It has a serious impact on resources and slows the scan. It's almost always not necessary. It Will only run javascript which is run on loading. Will not trawl javascript code for urls, or run javascript which is triggered by a user action, 'onClick' or scrolling for example.
Scanning a list of URLs
Rather than start at a url and crawl / spider a website, WebScraper can start with a list of URLs, scrape data from each of them.
Create a new project, then go to File > Open List of Links. Choose your list (.txt or .csv) and when you OK that dialog, WebScraper will ask whether you want to crawl each website in the list or limit the scan to only the urls in the list.
Authentication / sites that require login
WebScraper offers one simple method of authentication, It may not cover all cases but it's likely to work for most.
Switch on 'attempt authentication' and use the 'Login' button at the bottom of the Scan tab. This opens a browser window, loaded with your starting url. Assuming that your login form is shown, use it to log in. If this is successful, your authenticated status should last while WebScraper is open.
For obvious reasons it's very important to find your 'logout' url and blacklist it. In most cases this means setting up a rule along the links 'ignore urls that contain logout'
Output file format tab

This is where you configure the format of the file that you'll export, with some options.
Consolidate whitespace will remove unnecessary tabs, returns and spaces from your data. it's not unusual to end up with various whitespace characters lumped together after extracting plain text, markdown or using a regular expression.
The advanced options control various details of the CSV or JSON file.
Output filter tab

The scan may include all pages of your site, or an entire section. but you may only want to scrape data from certain pages.
The pages discovered during the crawl are fed here. The output filter determines which pages will be scraped. If you leave this tab empty, then you'll extract information from all pages (or all of the pages which were included in the scan). Only scrape data from pages where... allows you to specify which pages are scraped. You can enter a string for a partial match with url or content, or a regex, again for a match with url or content. You can enter more than one rule, and choose for them to be 'and' or 'or'
It is possible to specify 'information pages' here. ie if you've limited your scan (for example) to just pagination pages ('?page=') but the pages that you actually want information from are one click away, then urls that are matched in this table will override that scan blacklisting and will be scraped, but not followed for the purposes of the crawl.
Output file columns tab

If you have 'simple setup' selected then you won't see this tab. Instead there are a few simple selection controls below the Starting URL. You'll only see the Output file columns tab if you are switched to 'complex setup'.
The tab contains a table (regardless of whether you've chosen CSV or JSON output) and the columns will resemble the columns of a csv output.
By default, you get two columns configured to collect the URL and Title of each page. This is useful information to have in your exported file but you can delete those if you like.
You can add more columns with the [+] button and you'll see a dialog that allows you to select (as far as possible) what you want to extract. If you want to extract / scrape particular classes / ids or use a regular expression, then there are 'helpers' which are tools that help you find the class / id or write / test the regex.
The Run Test button will make a short scan and show you the results. It may or may not be enough for you to test that things are set up correctly. For a longer test, simply temporarily use the Stop at X Rows in the Results control on the Scan tab.
Note the checkboxes here which enable certain functions. If you want to download all images or PDF documents as the site is crawled, or end up with a list of link / image urls, then these things can be simply switched on. The checkboxes should be self-explanatory. For downloading images or pdf documents, and if you want to be selective based on the url, you can enter a partial url (items will be downloded if the term you type is a partial match) or a regular expression.
Results tab
This is a preview of your results. It appears as a table, even if you're not using CSV as the output format. One page = one row in the output at this point. See the comments below about splitting these onto separate rows
Post-process output file

Currently all options apply to CSV output format. These operations are performed after the scan, when the results are exported.
If you've got multiple data per page, then those data will be separated using the separator character specified on the Output file format tab (by default a pipe) and that's how they'll appear if exported as CSV. There is an option in the Post-process tab to split these multiple values onto separate rows when your file is exported.
If you've chosen JSON as your output format, that format allows for lists/arrays within objects, so those multiple data will automatically be separate in the output file.
Older versions of Excel and the current version of Numbers have a limit of 64,000 rows. Meaning that if your data exceeds that number, then it'll all be contained in the output file, but those particular spreadsheet apps won't display it all. In that case you can select Split into multiple files to choose to have your exported output split into multiple files of 64,000 rows each.
Remove rows where this column is empty: helps you to cleanse your output of rows where the column you're interested in is blank. The drop-down button should allow you to select any of the columns that you've set up in your Output file columns.
Class helper

You can access the helper from the Output file configuration dialog or from the View menu.
The right-hand pane shows the page which is your starting url. You can easily change the page that you're interested in, type or paste its url (top left) and press Refresh.
All of the classes and ids found in the pages's source will be listed in the table on the left, along with the result you'll get if you select that class/id. You can hover over this table to see that class indicated with a red box in the pane on the right. (You may need to single-click in the table first.)
if you see the class you want to use, double-click it in the table to close the helper and insert your expression into the Output file column setup dialog.
Regex helper

You can access the helper from the Output file configuration dialog or from the View menu.
The right-hand pane shows the page which is your starting url. You can easily change the page that you're interested in, type or paste its url (above the browser window) and press Refresh.
Type or paste your regular expression and press test. To help you, the page's source is displayed below the expression and result fields.
If your expression contains a collecting expression (in parentheses) then that collecting expression will be the result. If there's no collecting expression, and your expression makes a match, the entire match is the result.
A simple way to write an expression is to copy and paste a section of the code. Then select parts of that code and use the buttons below the Expression field to insert code. For example, (xyz) indicates text that you want to collect. (123) does the same where the result is a number. xyz incicates some text on the page that you want to ignore but will be different on each page. the button with the return arrow will replace whitespace in your expression.
When you're happy with your expression, press Use this to close the helper and insert your expression into the Output file column setup dialog.
Notes for experienced Regex users
Double quotes - simply use them in your expression. Escaping them by 'doubling up' won't work. An escape with a backslash will probably work but is unnecessary, If you include a double-quote character, WebScraper will assume you want to match that character.
Question? Don't be afraid to ask