
Scrutiny 12 Starting URL and Options
Optional options related to the scan
Within your site config listing, There are a few basic options under 'Options' and the more advanced options are under 'Rules' and 'Advanced'
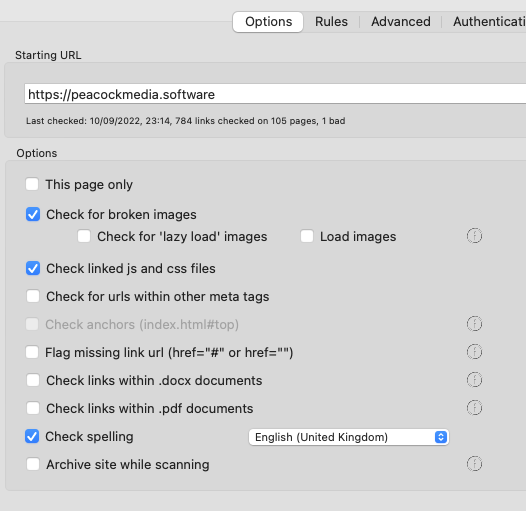
This page only
This checkbox allows you to scan a single page. Scrutiny will check the status of your starting url, check the status of all links found on it and stop there.
Check for broken images
(Now on by default.) The link check will also check for broken images (<img src=...) If alt text is present, it will be displayed in place of link text in the links reports.
Check for 'lazy load' images
'Lazyload' is being increasingly used. <img src=... may just contain a small placeholder allowing the page to finish loading quickly, while clientside scripting loads the full images. This isn't yet written into web standards, so it isn't guaranteed that Scrutiny will find your lazyload images. With this setting on, Scrutiny will look in some commonly-used places such as data-original and data-orig-src attributes to try to find the actual image urls.
Load images
This setting has limited value and will be detrimental to the scan. Requests for images will be allowed to continue to completion, so that the actual size of the image can be determined for the SEO report. Without this option on, we rely on information in the response header, which may well be the compressed size of the image and may not be present.
Check for broken linked js and css files
.js and .css files will be checked and reported. Linked resources (<link rel=...) will also be checked and reported with the link check results. With this option and 'check for broken images' switched on, the .css file will be parsed for url('...') images.
Check for urls within other meta tags
Certain other meta tags will be searched for urls, which will be checked and reported.
Check anchors
this will cause urls like /index.html#top and /index.html#bottom to be checked and reported as separate links (resulting in more data) and tested separately. (more cpu and time for crawl)
If the status is good, then Integrity makes a further check to see whether a name or id can be found on the target page matching the link fragment. If not, this is added to the link's warnings, and the link will be marked orange
Note that the anchor check is case-sensitive. Officially anchors are case-sensitive. Some browsers may treat anchors as case-insensitive, but this doesn't mean that all browsers will and it doesn't mean that it's right.
Note that you can't 'ignore querystrings' and also test the anchors, since the anchor fragment comes after the querystring. So if this option is greyed out, that's probably because the 'ignore querystrings' is on.
The filter button contains 'Warnings' which shows only links with warnings, this will include links with anchors where the anchor (a name or an id) can't be found on the page
Type a '#' into the search field to show links which contain a #fragment.
Flag missing link url
When a website is being developed, link targets may sometimes be left blank or a placeholder such as # used. (<a href = "" ) If you'd like to find such empty link targets, switch this setting on and they'll be highlighted as if they were bad links. With the setting off, they will be ignored.
Check links within pdf / docx documents
With these options on, a pdf and/or docx document on your site will be loaded and parsed for links as if it were a web page. Beware - these documents can be much bigger than web pages.
For opening a pdf or docx document as a starting url, see list.html#docs.
Spelling
Check spelling and grammar of a page's content during the scan. This takes time and resources (particularly grammar) so don't switch on unless you want spell-check or grammar results. Spell checking isn't too much of an overhead but grammar really is, especially if there's a significant amount of text on your page. The languages selector offers languages installed on your computer, and standard MacOS functionality is used for the checks. Scrutiny will use your existing custom dictionary (learned words) if it exists.
Archive pages while crawling
Since v12, the archive functionality is upgraded to that of Website Watchman.
It'll store the data while it scans (including supporting files such as images, css and js) and save it off to disc at the end of the scan (asking you for a location). You'll have the option to 'Preserve' or 'Process'. If you want to save the files exactly as they're received, choose Preserve. If you want to browse the site from the local archive, choose Process.