
Scrutiny 12 Per-site Rules
Rules governing the scope of the scan
Rules - Ignore / Do not check / Do not follow
(Previously known as blacklists and whitelists)
In a nutshell, 'check' means ask the server for the status of that page without actually visiting the page. 'Follow' means visit that page and scrape the links off it.
Checking a link means sending a request and receiving a status code (200, 404, whatever). Scrutiny will check all of the links it finds on your starting page. If you've checked 'This page only' then it stops there.
Otherwise, it'll take each of those links it's found on your first page and 'follow' them. That means it'll request and load the content of the page, then trawl the content to find the links on that page. It adds all of the links it finds to its list and then goes through those checking them, and if appropriate, following them in turn.
Note that it won't 'follow' external links, because it would then be crawling someone else's site, which we don't want. It just needs to 'check' external links but not 'follow' them.
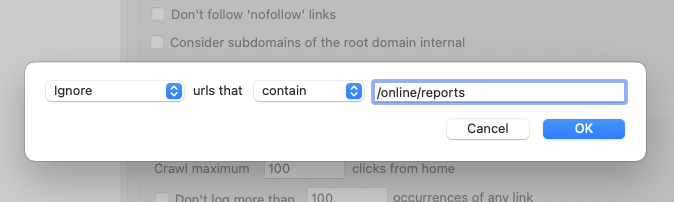
You can ask Scrutiny to ignore certain links, not check certain links or not to follow certain links. You can now also choose 'urls that contain' / 'urls that don't contain'
This works by typing a partial url. For example, if you want to only check pages on your site containing /manual/ you would choose 'Do not follow...', choose 'urls that don't contain' and type '/manual/' (without quotes). You don't necessarily need to know about pattern matching such as regex or wildcards, just type a part of the url.
Scrutiny supports some pattern matching functionality to the rules. This is limited to * for 'any number of any characters' and $ meaning 'at the end', eg /*.php$
You can limit the crawl based on keywords or a phrase that appear in the content by checking that box.
You can highlight pages that are matched by the 'do not follow' or 'only follow' rules. This option is on the first tab of Preferences under Labels. (Flag blacklisted (or non-whitelisted) urls)
Limit crawl based on robots.txt
The robots.txt file at the root of your website gives instructions to bots; which directories or urls are disallowed. Scrutiny can observe this file if you choose.
If robots.txt contains separate instructions for different search engines, Scrutiny will observe instructions for Googlebot, or failing that, '*'
Ignore external links
This setting makes Scrutiny a little more efficient if you're only interested in internal links (if you're 'creating a sitemap, for example)
Don't follow 'nofollow' links
This specifically refers to the the 'rel = nofollow' attribute within a link, not the robots meta tag within the head of a page. With this setting on, links that are nofollow will be listed and checked, but not followed.
To check for nofollow in links, you can switch on a nofollow column in the 'by link' or 'flat view' links tables. With the column showing in either view, Scrutiny will check for the attribute in links and show Yes or No in the table column. (You can of course re-order the table columns by dragging and dropping).
Consider subdomains of the root domain internal
foo.com and m.foo.com are considered the same site as www.foo.com with this setting switched on.
Limiting Crawl
If your site is big enough or if Scrutiny hits some kind of loop (there are a number of reasons why any webcrawler can run into a recursive loop) it would eventually run out of resources. These limits exist to prevent Scrutiny running for ever, but they have quite high defaults.
By default it's set to stop at 2 million links. Scrutiny will probably handle many more, depending on your settings, but it's a useful safety valve and may stop the crawl in cases where Scrutiny has found a loop.
(Scrutiny has low disc space detection to prevent a crash caused for this reason.) If the low disk space alert is shown, then it'll be necessary to break down the site usng rules (blacklisting / whitelisting).
Besides the number of links found, you can also specify the number of 'levels' that Scrutiny will crawl (clicks from home, sometimes known as 'depth').
If a link appears on every page or many pages of a large site, storing the details of those occurrences can take a lot of space. If there are very many occurrences of a link then it's very likely that it's part of a template, and you won't need to know exactly which pages it appears on anyway. This setting makes the scan more efficient.
These settings can be set 'per site' but the defaults for new configurations are set in Preferences